Closing the Latency Gap: Decart Is Helping Shape the AI Grid
Decart is collaborating with Comcast to move high-performance inference to the edge powered by Nvidia GPUs – enabling sub-35ms generative AI experiences.

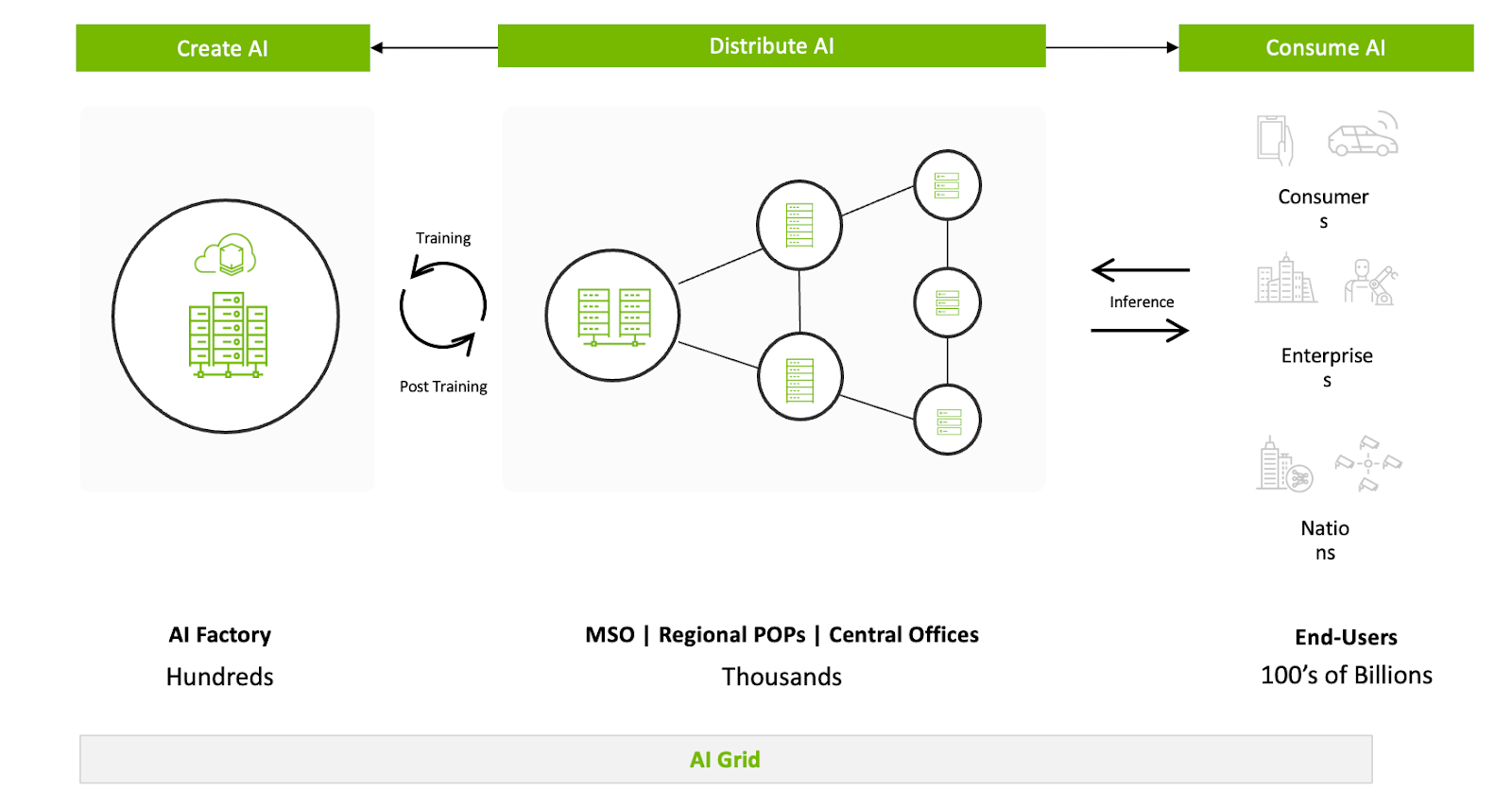
AI-Grid: Leveraging existing trusted assets to enable inference at scale
The promise of Lucy model and our other world models is "zero-latency" immersion. But even when our model generates a frame in under 30ms, the physics of the internet can get in the way. Centralized data centers under congestion—no matter how powerful they are—introduce jitter, and geographic distance that can break the flow of a real-time stream while scaling.
As part of exploring new mitigation for this problem, Decart is collaborating with Comcast and NVIDIA to shape the future AI Grid: a distributed infrastructure designed to move high-intense inference workloads from centralized hubs to the network edge. By benchmarking the Lucy model on NVIDIA’s architectures within Comcast’s distributed network, we’ve shown that real-time AI isn't just model speed—it’s the architecture of the compute “grid” itself.
"Today, Distributed Compute on Edge is a missing piece for generative AI. By benchmarking Lucy on NVIDIA GPUs within Comcast’s network, we’ve proven we can deliver high-fidelity, real-time AI with sub-12ms network latency. This is a fundamental shift in how generative media is delivered and experienced." — [ Menash Land, Cloud Business & Strategy at Decart]
The Problem: The Centralized Cloud Bottleneck
Traditional cloud architectures were built for throughput, not for the ultra-fast responsiveness required by world models. When millions of users interact with a real-time model simultaneously, centralized data centers experience:
- Network Jitter: Fluctuations in packet delivery that cause dropped frames and "stuttering" in the video stream.
- Congestion Risks: Mass usage of high-bandwidth generative workloads leads to significant latency spikes during peak hours.
- Baseline Latency: Even at the speed of light, every mile of fiber between the user and the GPU adds milliseconds of latency that might harm user experience, or robot functionality.
Because every frame generated by Lucy is a unique, live transformation based on a specific user prompt and often a live video stream, edge caching is impossible. Unlike traditional video streaming, every bit here is unique. This makes the distributed architecture ideal for scaling; when datacenters become congested, the resulting 'heavy tail' of jitter will make centralized inference greatly suffer for real-time interaction.
Our testing confirmed that for mass-scale, real-time generative applications, the centralized model eventually leads to a deteriorated Quality of Experience (QoE). To scale, we had to move the compute closer to the glass.
Benchmarking the Future
We didn't just move the code to the edge; we optimized the entire stack for it while performing extensive benchmarking, to ensure that Decart’s models utilize every ounce.
Our benchmarking was conducted on a controlled environment to isolate network performance from environmental variables.
Key technical milestones from our validation include:
- Sub-12ms Edge Latency: By moving compute to an edge node within Comcast’s network, we reduced round-trip network time to ~20ms. This makes the AI feel "local" to the user, but actually leveraging robust cloud-accelerators.
- The System Performance: The system achieved a steady 29-30 FPS, which proves that when the network is 'invisible,' the GPU can drive a high-fidelity interactive experience at native refresh rates.
Pipelined Inference Efficiency & The Jitter Buffer:
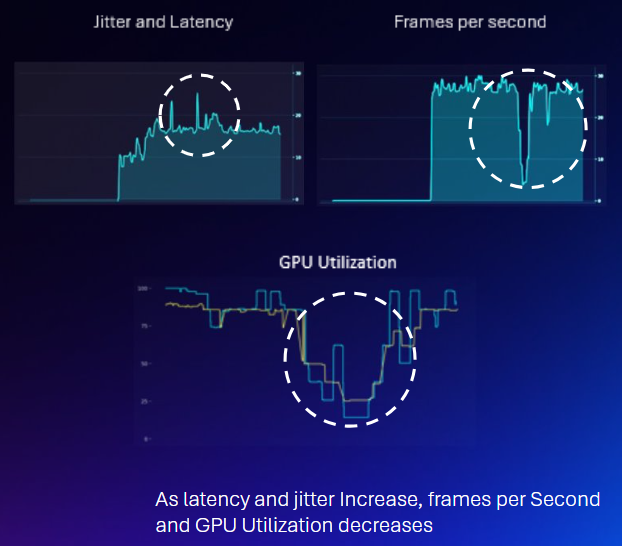
In theory, high network jitter causes the FPS of the input stream to fluctuate. When a GPU is driven to its maximum possible throughput, these fluctuations usually force the hardware to either drop frames or sit idle while waiting for the next packet.
Contrary to our initial hypothesis that network latency would cause GPU idling, our benchmarks showed that GPU utilization remained locked at 90–100%.
This is made possible by Decart's pipeline, which features an adaptive jitter buffer leveraging WebRTC implementation. By dynamically adjusting to network conditions, the buffer supplies a perfectly steady stream of frames to the GPU. This masks the network round-trips to make sure the hardware is not starved for data.
The "Jitter Cliff": The Latency Tax and Failure Points
While our adaptive buffer ensures stability, it isn't "free." To handle the extreme end of the latency distribution (the "long tail"), we pay a Latency Tax.
- The Latency Tax: To prevent GPU idling, the jitter buffer adds an artificial delay to the output stream. This delay is tuned to cover the variance in the distribution, meaning the user experiences the average network latency plus the buffer's safety margin.
- The Failure Point: In our "Cloud Resilience" tests (30ms added latency with 10ms jitter), the buffer maintained a consistent 29-30 FPS. However, when simulating extreme congestion with "unreal" jitter values of 45ms, the adaptive buffer hit its physical limit.
When the fluctuations exceed the buffer's capacity to compensate, we hit a performance cliff. Frame rates collapsed to 14-17 FPS with frequent drops. This data proves there is a hard ceiling for software-based mitigation; beyond a certain threshold of network variance, the only way to eliminate the "latency tax" and maintain stability is through physical proximity—the AI Grid.
Unlocking the Next Generation of Use Cases
The AI Grid doesn't just make current workloads stable under massive traffic—it unlocks categories of applications that were previously impossible due to the "latency tax."
1. Hyper-Responsive Interactive Media When latency stays below the human perception threshold (<12ms network-side), generative video feels like a physical extension of the user’s input. This enables personalized visual synthesis where every pixel reacts instantly to your voice or movement.
2. High-Frequency Robotics Reasoning Modern robotics require high-frequency visual feedback loops. By running Lucy-powered simulation and data augmentation at the edge, we can provide robots with real-time "visual reasoning" that isn't throttled by the lag of a distant server.
3. Immersive Digital Environments Whether it’s a virtual try-on or a live character swap, the AI Grid ensures that the "soul" of the character – remains perfectly synced with the visual world, even on consumer-grade connections.
What’s Next?
Decart is committed to making generative AI truly real-time and interactive. The AI Grid is a great foundation for moving toward "living worlds." We are continuing to work with our partners to expand this footprint, ensuring that wherever you are, the fastest visual AI in the world is only a few milliseconds away.
Want to already see what near-zero-latency feels like? Try our latest models at decart.ai
To read more about the partnership, please see: